
 512 お客様のコメント
512 お客様のコメント
質問 1:
There is a two-node cluster with Node1 and Node2. An administrator changes filesystem size on Node1 by using the chfs command, and moves resource the group to Node2.
The administrator finds the change of filesystem size is recognized on Node2.
Why is the filesystem size change reflected on Node2?
A. The filesystem size change is recognized when filesystem is mounted on Node2.
B. The gsclvmd daemon automatically synchronizes filesystem changes.
C. A pre-event is defined to get_disk_vg_fs event to reflect filesystem size change.
D. The shared volume group is re-imported on Node2 by lazy update when moving the resource group.
正解:D
質問 2:
In which configuration would an AIO Cache LV be required?
A. When using mirror pools
B. Cross-site LVM
C. Synchronous GLVM
D. Asynchronous GLVM
正解:A
質問 3:
After changing a PowerHA 6 cluster to reflect new IP addresses, an administrator attempts to synchronize a cluster and receives the following message:
cldare: A communication error prevents obtaining the VRMF from remote nodes. A DARE cannot be run until this is corrected. Please ensure clcomd is running.
How can the administrator correct this error?
A. Include the new IP addresses in /.rhosts on all cluster nodes.
B. Include the new IP addresses in /etc/hosts.equiv on all cluster nodes.
C. Include the new IP addresses in /usr/es/sbin/cluster/etc/rhosts on all cluster nodes.
D. Include the new IP addresses in /usr/es/sbin/cluster/etc/clhosts on all cluster nodes.
正解:C
質問 4:
An administrator is adding a new resource group for a database environment that has nested filesystems. How should the "Filesystems Recovery Method" option be set to ensure they are mounted properly?
A. Serial
B. All
C. Sequential
D. Parallel
正解:C
質問 5:
The db_group resource group become unmanaged after cluster service on node1 is forced down. Which action will change the state of db_group resource group from unmanaged to Online on node2?
A. Move resource group db_group from node1 to node2
B. Run clchres utility to change the state of db_group resource to Online on node2
C. Bring db_group Online directly on node2
D. Bring db_group offline and then bring db_group Online on node2
正解:D
質問 6:
The service IPs VLAN is the only routable network in a 2-node HA cluster with multiple network interfaces.
What must done to enable administrative tasks to be performed remotely on the cluster nodes?
A. Configure a persistent IP Address for each node on the service IP network.
B. Associate a permanent Service IP address for each HA node.
C. Create a route on the switch and translate the Service IP address to the boot IP address using NAT.
D. Configure the boot IP Address on the same VLAN as the service IP Address.
正解:A
質問 7:
Consider the following PowerHA DLPAR configuration for a cluster, and LPAR profile on the HMC for a standby node in that cluster:
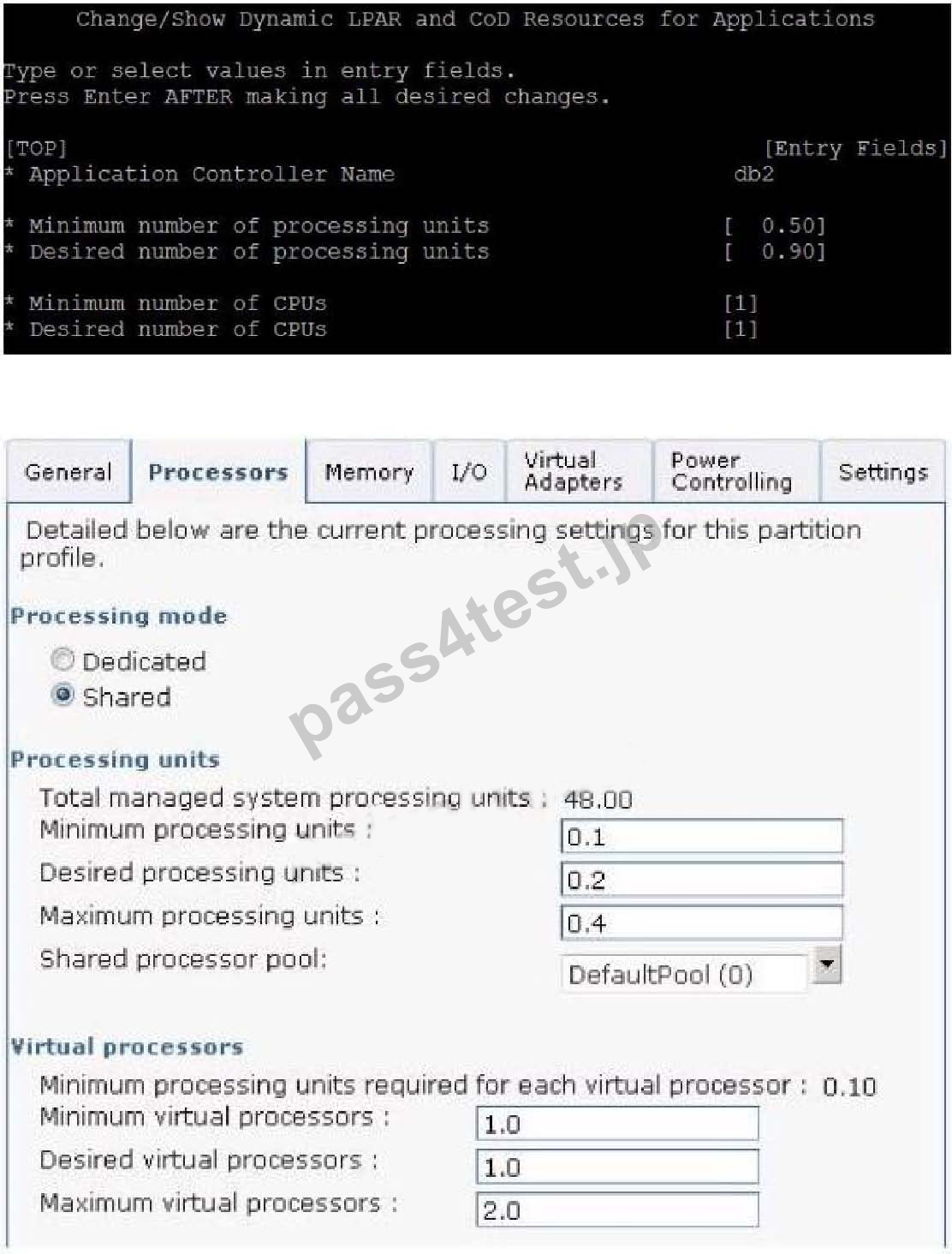
How should the standby node profile be reconfigured so that an application runs with the minimum
hardware resources?
A. Minimum processing units = 0.5 and both Desired and Maximum processing units = 0.9
B. Minimum processing units = 0.6 and both Desired and Maximum processing units = 1.5
C. Minimum and Desired processing units = 0.1 and Maximum processing units = 0.6
D. Minimum and Desired processing units = 0.2 and Maximum processing units = 0.5
正解:B
質問 8:
The /usr/es/sbin/cluster/netmon.cf file contains the following lines:
IREQD host1.ibm 100.12.7.9
IREQD host1.ibm host4.ibm
What is the effect of this configuration?
A. The node will only be considered "up" if it can ping at least one address on each line.
B. The interface will only be considered "up" if it can ping 100.12.7.9 OR the address to which host4.ibm resolves.
C. The interface will only be considered "up" if it can ping 100.12.7.9 AND the address to which host4.ibm resolves.
D. The node will only be considered "up" if it can ping all addresses on the first line AND all addresses on the second line
正解:B
There is a two-node cluster with Node1 and Node2. An administrator changes filesystem size on Node1 by using the chfs command, and moves resource the group to Node2.
The administrator finds the change of filesystem size is recognized on Node2.
Why is the filesystem size change reflected on Node2?
A. The filesystem size change is recognized when filesystem is mounted on Node2.
B. The gsclvmd daemon automatically synchronizes filesystem changes.
C. A pre-event is defined to get_disk_vg_fs event to reflect filesystem size change.
D. The shared volume group is re-imported on Node2 by lazy update when moving the resource group.
正解:D
質問 2:
In which configuration would an AIO Cache LV be required?
A. When using mirror pools
B. Cross-site LVM
C. Synchronous GLVM
D. Asynchronous GLVM
正解:A
質問 3:
After changing a PowerHA 6 cluster to reflect new IP addresses, an administrator attempts to synchronize a cluster and receives the following message:
cldare: A communication error prevents obtaining the VRMF from remote nodes. A DARE cannot be run until this is corrected. Please ensure clcomd is running.
How can the administrator correct this error?
A. Include the new IP addresses in /.rhosts on all cluster nodes.
B. Include the new IP addresses in /etc/hosts.equiv on all cluster nodes.
C. Include the new IP addresses in /usr/es/sbin/cluster/etc/rhosts on all cluster nodes.
D. Include the new IP addresses in /usr/es/sbin/cluster/etc/clhosts on all cluster nodes.
正解:C
質問 4:
An administrator is adding a new resource group for a database environment that has nested filesystems. How should the "Filesystems Recovery Method" option be set to ensure they are mounted properly?
A. Serial
B. All
C. Sequential
D. Parallel
正解:C
質問 5:
The db_group resource group become unmanaged after cluster service on node1 is forced down. Which action will change the state of db_group resource group from unmanaged to Online on node2?
A. Move resource group db_group from node1 to node2
B. Run clchres utility to change the state of db_group resource to Online on node2
C. Bring db_group Online directly on node2
D. Bring db_group offline and then bring db_group Online on node2
正解:D
質問 6:
The service IPs VLAN is the only routable network in a 2-node HA cluster with multiple network interfaces.
What must done to enable administrative tasks to be performed remotely on the cluster nodes?
A. Configure a persistent IP Address for each node on the service IP network.
B. Associate a permanent Service IP address for each HA node.
C. Create a route on the switch and translate the Service IP address to the boot IP address using NAT.
D. Configure the boot IP Address on the same VLAN as the service IP Address.
正解:A
質問 7:
Consider the following PowerHA DLPAR configuration for a cluster, and LPAR profile on the HMC for a standby node in that cluster:
How should the standby node profile be reconfigured so that an application runs with the minimum
hardware resources?
A. Minimum processing units = 0.5 and both Desired and Maximum processing units = 0.9
B. Minimum processing units = 0.6 and both Desired and Maximum processing units = 1.5
C. Minimum and Desired processing units = 0.1 and Maximum processing units = 0.6
D. Minimum and Desired processing units = 0.2 and Maximum processing units = 0.5
正解:B
質問 8:
The /usr/es/sbin/cluster/netmon.cf file contains the following lines:
IREQD host1.ibm 100.12.7.9
IREQD host1.ibm host4.ibm
What is the effect of this configuration?
A. The node will only be considered "up" if it can ping at least one address on each line.
B. The interface will only be considered "up" if it can ping 100.12.7.9 OR the address to which host4.ibm resolves.
C. The interface will only be considered "up" if it can ping 100.12.7.9 AND the address to which host4.ibm resolves.
D. The node will only be considered "up" if it can ping all addresses on the first line AND all addresses on the second line
正解:B






Miyazaki -
C4040-332試験問題集の的中率は高いで、とても有効的な資料です。今度、C4040-332試験に合格しました。ありがとう!