
 525 お客様のコメント
525 お客様のコメント
質問 1:
You would like to invoke a job sequence from a web service. How can this be done?
A. Create a DataStage routine that invokes the job sequence and invoke the routine from a DataStage job. Then use this job when creating the web service operation.
B. Invoke the job sequence using the dsjob command.
C. Select the job sequence when creating the web service operation,
D. Check the use job sequence checkbox when creating the web service.
正解:A
質問 2:
You are describing to your customer how to work with packages. There are two steps that must be carried out in order to move the package to a target project. Which two steps must be carried out to move the DataStage objects to the Production system? (Choose two.)
A. Build
B. Export
C. Package
D. Deploy
E. Compile
正解:A,D
質問 3:
You are asked by management to document all jobs written to make future maintenance easier. Which two statements are true about annotations? (Choose two.)
A. The Description Annotation stage can be added several times at different locations to identify business logic.
B. The Description Annotation stage contains both the short and full descriptions for the job.
C. The full job description can be identified within the Description Annotation stage.
D. The background for the Description Annotation stage can be changed for each unique stage.
正解:B,C
質問 4:
A DataStage job uses an Inner Join to combine data from two source parallel datasets that were written to disk in sort order based on the join key columns. Which two methods could be used to dramatically improve performance of this job? (Choose two.)
A. Set the environment variable $APT_SORT_INSERTION_CHECK_ONLY.
B. Unset the Preserve Partitioning flag on the output of each parallel dataset.
C. Explicitly specify hash partitioning and sorting on each input to the Join stage.
D. Disable job monitoring.
E. Add a parallel sort stage before each Join input, specifying the "Don't Sort, Previously Grouped" sort key mode for each key.
正解:A,E
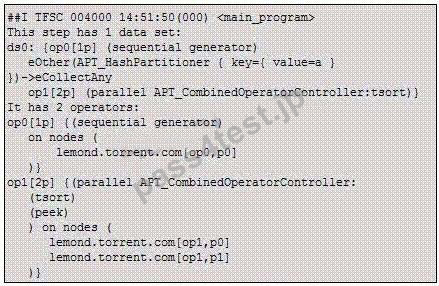
質問 5:
Click the exhibit button.

You submit a job from DataStage Director and then log onto your DataStage Linux server to issue the command "ps -ef | grep ds" and receive the following screen: Which process is a player?
A. 7217
B. 7215
C. 7216
D. 7117
正解:A
質問 6:
Your job sequence must be restartable. It runs Job1, Job2, and Job3 serially. It has been compiled with "Add checkpoints so sequence is restartable". Job1 must execute every run even after a failure. Which two properties must be selected to ensure that Job1 is run each time, even after a failure? (Choose two.)
A. In the Job1 Activity stage set the Execution action to "Reset if required, then run.".
B. Set trigger on the Job1 Activity stage to "Unconditional".
C. Use the Nested Condition Activity with a trigger leading to Job1; set the trigger expression type to "Unconditional".
D. Set the Job1 Activity stage to "Do not checkpoint run.".
正解:A,D
質問 7:
The purchase history record contains CustID, ProductID, ProductType and TotalAmount. You need to retain the record of greatest TotalAmount per CustID and ProductType using RemoveDuplicate stage. Which two statements accomplish this requirement? (Choose two.)
A. Hash-partition on ProductType;
Sort on ProductType, CustID and TotalAmount.
B. Hash-partition on CustID;
Sort on CustID, ProductType and TotalAmount.
C. Hash-partition on CustID and ProductType;
Sort on CustID, ProductType and TotalAmount.
D. Hash-partition on CustID, ProductType and TotalAmount;
Sort on CustID, ProductType and TotalAmount.
正解:B,C
You would like to invoke a job sequence from a web service. How can this be done?
A. Create a DataStage routine that invokes the job sequence and invoke the routine from a DataStage job. Then use this job when creating the web service operation.
B. Invoke the job sequence using the dsjob command.
C. Select the job sequence when creating the web service operation,
D. Check the use job sequence checkbox when creating the web service.
正解:A
質問 2:
You are describing to your customer how to work with packages. There are two steps that must be carried out in order to move the package to a target project. Which two steps must be carried out to move the DataStage objects to the Production system? (Choose two.)
A. Build
B. Export
C. Package
D. Deploy
E. Compile
正解:A,D
質問 3:
You are asked by management to document all jobs written to make future maintenance easier. Which two statements are true about annotations? (Choose two.)
A. The Description Annotation stage can be added several times at different locations to identify business logic.
B. The Description Annotation stage contains both the short and full descriptions for the job.
C. The full job description can be identified within the Description Annotation stage.
D. The background for the Description Annotation stage can be changed for each unique stage.
正解:B,C
質問 4:
A DataStage job uses an Inner Join to combine data from two source parallel datasets that were written to disk in sort order based on the join key columns. Which two methods could be used to dramatically improve performance of this job? (Choose two.)
A. Set the environment variable $APT_SORT_INSERTION_CHECK_ONLY.
B. Unset the Preserve Partitioning flag on the output of each parallel dataset.
C. Explicitly specify hash partitioning and sorting on each input to the Join stage.
D. Disable job monitoring.
E. Add a parallel sort stage before each Join input, specifying the "Don't Sort, Previously Grouped" sort key mode for each key.
正解:A,E
質問 5:
Click the exhibit button.
You submit a job from DataStage Director and then log onto your DataStage Linux server to issue the command "ps -ef | grep ds" and receive the following screen: Which process is a player?
A. 7217
B. 7215
C. 7216
D. 7117
正解:A
質問 6:
Your job sequence must be restartable. It runs Job1, Job2, and Job3 serially. It has been compiled with "Add checkpoints so sequence is restartable". Job1 must execute every run even after a failure. Which two properties must be selected to ensure that Job1 is run each time, even after a failure? (Choose two.)
A. In the Job1 Activity stage set the Execution action to "Reset if required, then run.".
B. Set trigger on the Job1 Activity stage to "Unconditional".
C. Use the Nested Condition Activity with a trigger leading to Job1; set the trigger expression type to "Unconditional".
D. Set the Job1 Activity stage to "Do not checkpoint run.".
正解:A,D
質問 7:
The purchase history record contains CustID, ProductID, ProductType and TotalAmount. You need to retain the record of greatest TotalAmount per CustID and ProductType using RemoveDuplicate stage. Which two statements accomplish this requirement? (Choose two.)
A. Hash-partition on ProductType;
Sort on ProductType, CustID and TotalAmount.
B. Hash-partition on CustID;
Sort on CustID, ProductType and TotalAmount.
C. Hash-partition on CustID and ProductType;
Sort on CustID, ProductType and TotalAmount.
D. Hash-partition on CustID, ProductType and TotalAmount;
Sort on CustID, ProductType and TotalAmount.
正解:B,C






Asakura -
これ問題集で充分対応できそう。Pass4Testありがとうございます。知識もしっかりと身につくと思います。